OpenAI has launched an advanced suite of AI models under the GPT-4.1 banner, which surpasses the capabilities of its predecessors. Despite the numerical shift from GPT-4.5 to GPT-4.1, this progression marks a significant enhancement in model performance and utility. Initially limited in application, these AI models excel in coding and instruction adherence, offering distinct advantages over earlier versions.
The GPT-4.1 series comprises three variations: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. Each supports an expanded context of up to 1 million tokens, showcasing notable improvements in encoding, command following, and long-context comprehension. Furthermore, these models offer cost efficiency and expedited processing relative to earlier versions.
April 14, 2025, marked the debut of these groundbreaking models, each tailored for specific applications despite their shared architecture:
GPT-4.1
Positioned as the flagship, GPT-4.1 is designed for optimal performance in coding, instruction adherence, and handling extensive contextual tasks. It efficiently manages intricate coding scenarios and large documents within a single request. In performance assessments, it outshines GPT-4o across numerous benchmarks, including real-world software engineering (SWE-bench), complex instruction following (MultiChallenge), and long-context reasoning (MRCR, Graphwalks). Expanded to accommodate up to one million tokens, it also supports fine-tuning for specialized applications requiring nuanced control over tone, format, or domain-specific knowledge.
GPT-4.1 Mini
The GPT-4.1 mini offers a balanced option, nearly matching the full model’s capabilities with reduced latency and cost. It excels in benchmarks, particularly in instruction adherence and image-based reasoning. This model is agile enough for interactive applications, adept at detailed instructions, and significantly more cost-effective than its larger counterpart. Like its full version, it supports a million-token context and can be fine-tuned. While maintaining performance akin to the GPT-4o, latency is nearly halved and costs are reduced by 83%, signaling substantial advancements in smaller model efficacy.
GPT-4.1 Nano
The GPT-4.1 nano emerges as the most compact, swiftest, and economical model in the lineup. It is particularly suited for tasks like autocompletion, classification, and extracting information from extensive documents. Despite its compactness, it handles the full 1 million-token context and surpasses the GPT-4o mini in various benchmarks. As OpenAI’s most affordable model (10 cents per million tokens), it is ideal for low-latency applications, although initially unavailable for fine-tuning, which is anticipated soon.
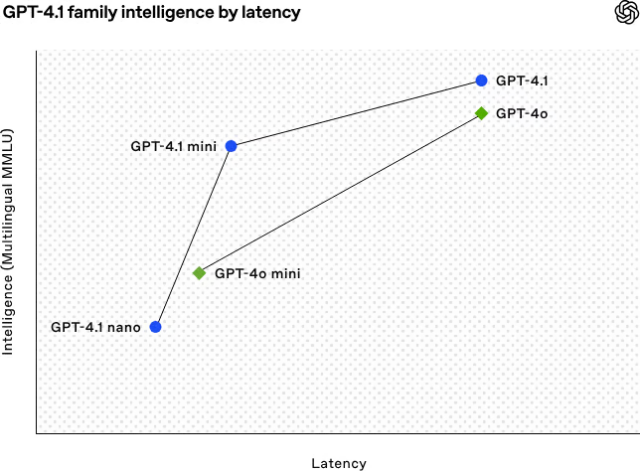
The GPT-4.1 models improve upon the GPT-4o’s capabilities while maintaining similar latency, offering developers enhanced performance without compromising responsiveness. The GPT-4.1 mini outperforms its predecessor with minimal latency increase. The GPT-4.1 nano excels in speed, tailored for lightweight, speed-prioritized tasks over raw reasoning prowess.
While GPT-4.5 served as a research preview with robust reasoning but higher overhead, GPT-4.1 matches or exceeds its benchmark results at a reduced cost and enhanced responsiveness. OpenAI plans to phase out GPT-4.5 by mid-July to allocate more GPU resources efficiently.
1 Million Tokens of Context
Each model within the GPT-4.1 family—standard, mini, and nano—supports a context of up to 1 million tokens, a substantial increase from GPT-4o’s offerings. This extended context capacity facilitates practical applications such as processing entire logs, indexing code repositories, managing multi-document legal workflows, or analyzing extensive transcripts without pre-shredding or summarizing.
Enhanced Instruction Adherence
Significant strides have been made in the models’ ability to follow instructions reliably. They manage complex prompts with sequential instructions, formatting constraints, and negative conditions, such as refusing to proceed with incorrect formatting, effectively reducing both prompt preparation time and post-processing of outputs.
The GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano are accessible exclusively via the OpenAI API and are not available through the regular chat application. Developers can explore these models via the OpenAI Playground, enabling iteration on system prompts, testing multi-step outputs, and assessing model performance on long documents or structured inputs before production integration.
Coding Advancements
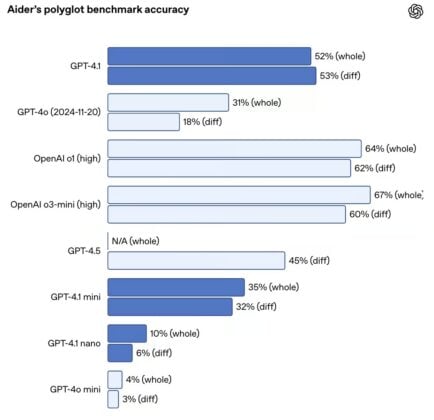
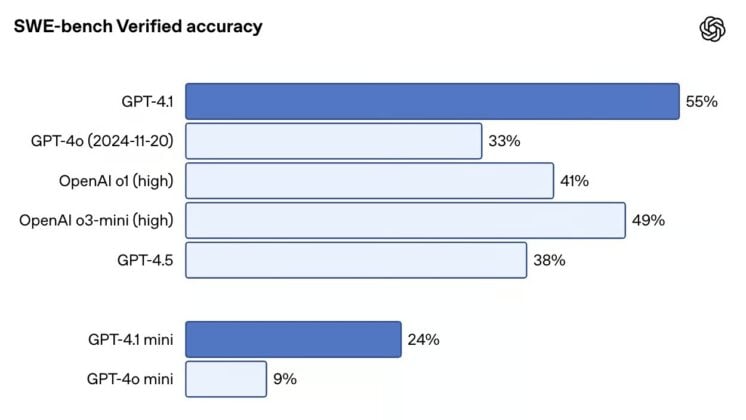
In the SWE-bench Verified benchmark, testing end-to-end issue completion on real codebases, GPT-4.1 scored 54.6%, outpacing GPT-4o’s 33.2% and GPT-4.5’s 38%. It also excels in multilingual code diffs, achieving 52.9% accuracy, an improvement over GPT-4.5’s 44.9%. Precision in coding is enhanced, reducing unnecessary edits from 9% (GPT-4o) to 2%.
OpenAI’s coding demo visually illustrates GPT-4.1’s superior performance, with reviewers preferring its output 80% of the time. Companies like Windsurf and Qodo report significant improvements in internal encoding benchmarks and GitHub recommendations, respectively.

Instruction Following
GPT-4.1 demonstrates heightened realism and reliability in following complex instructions. In OpenAI’s internal evaluations, it scores 49.1% in instruction following (hard subset), significantly higher than GPT-4o’s 29.2%. Though slightly trailing behind GPT-4.5’s 54%, the improvement over GPT-4o is substantial.
In the MultiChallenge test, GPT-4.1 improves adherence to multi-step instructions, increasing from 27.8% to 38.3%. In IFEval, which tests compliance with explicit output requirements, it scores 87.4%, surpassing GPT-4o’s 81%, showcasing better adherence to sequential steps and structured output formats.
Long Context Reasoning
All three GPT-4.1 models handle up to 1 million tokens of context, without additional cost for extended contexts. In OpenAI’s needle-in-a-haystack evaluation, GPT-4.1 reliably identifies content at any point within a million-token input. In Graphwalks, testing multi-hop reasoning, GPT-4.1 scores 61.7%, a significant leap from GPT-4o’s 41.7%, slightly below GPT-4.5’s 72.3%.
Real-world testing corroborates these improvements. Thomson Reuters reports a 17% increase in multi-document legal analysis using GPT-4.1, while Carlyle notes a 50% improvement in data extraction from detailed financial reports.
Multi-Modal and Vision Tasks
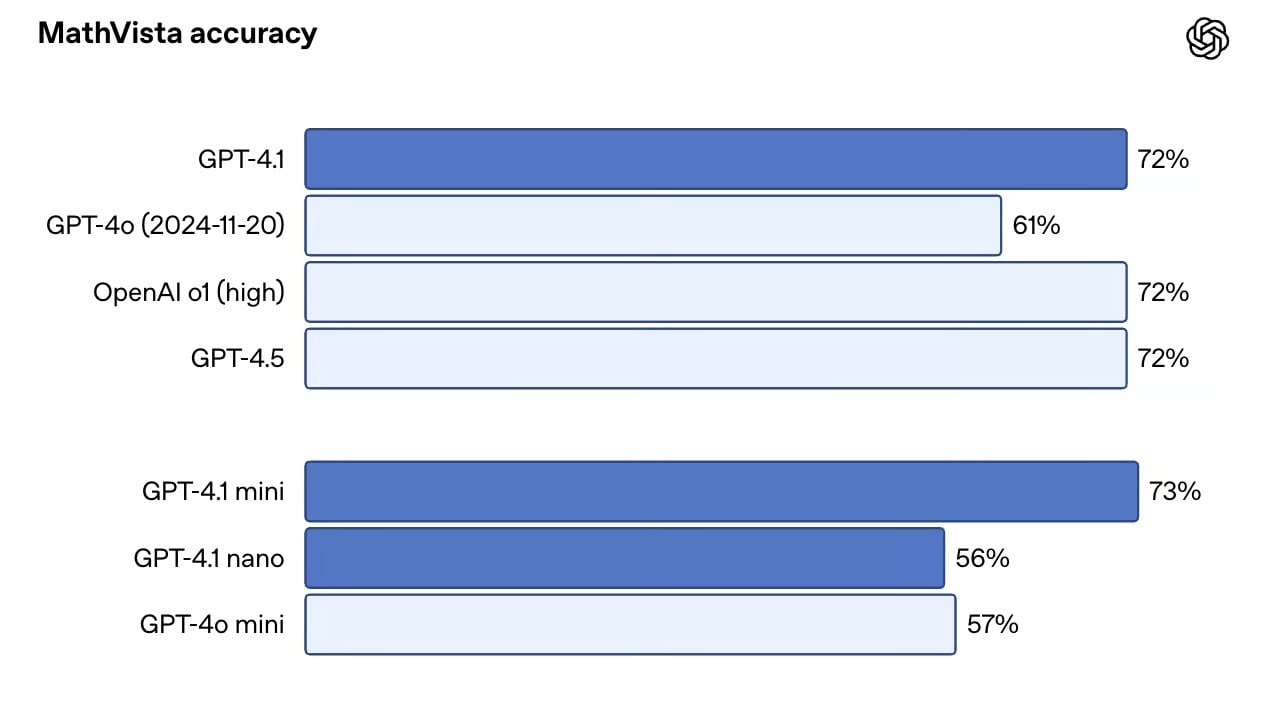
GPT-4.1 advances in multimodal tasks. In the Video-MME benchmark, addressing questions about 30-60 minute videos without subtitles, GPT-4o achieves a 72.0% accuracy, up from 65.3%. For image-heavy benchmarks like MMMU, GPT-4o scores 74.8%, improving from 68.7%. In MathVista, involving charts and math visuals, GPT-4.1 scores 72.2%.
The GPT-4.1 mini performs comparably well, even surpassing the full version in MathVista with a score of 73.1%, making it a compelling choice for tasks requiring speed and image processing capabilities.
























